The Problem
The tidyREDCap package creates data sets with labelled
columns.
tidyREDCap::import_instruments(
url = "https://bbmc.ouhsc.edu/redcap/api/",
token = keyring::key_get("REDCapR_test")
)If you would like to see the labels on the data set
demographics, you can use the RStudio function
View(), as shown below.
View(demographics)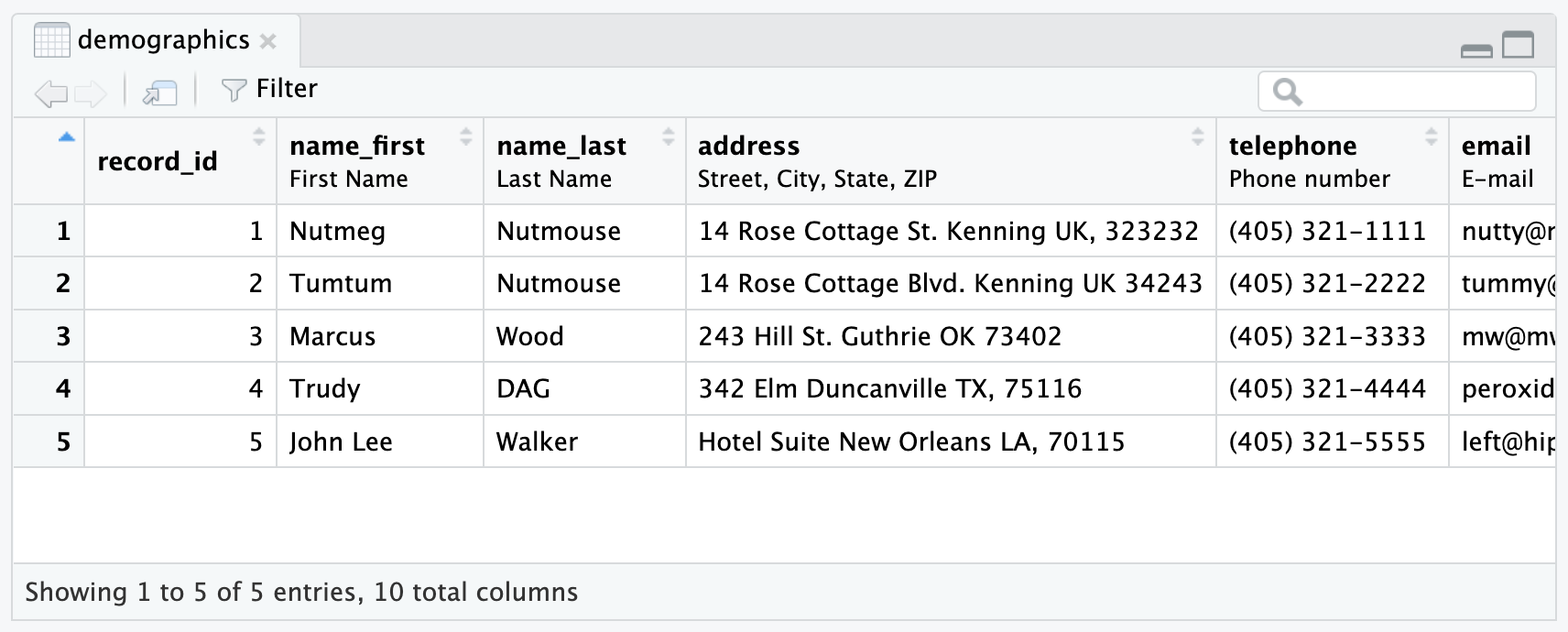
However, some functions do not work well with labeled variables. For example:
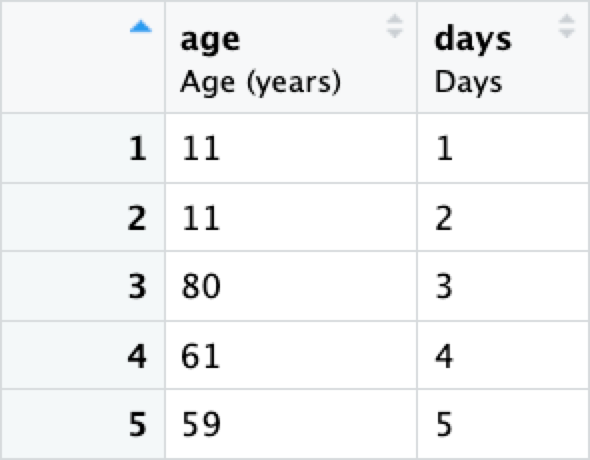
demographics |>
rowwise() |>
mutate(x = sum(c_across(c(age, days))))
#> Error in `mutate()`:
#> ℹ In argument: `x = sum(c_across(c(age, days)))`.
#> ℹ In row 1.
#> Caused by error in `vec_cast.labelled.labelled()`:
#> ✖ You are trying to combine variables with different labels
#> You can use tidyREDCap::drop_label() to erase one.So you need a way to drop the label off of a variable or to drop all the labels from all the variables in a dataset.
The Solution
Drop a single label
You can drop the label from a single variable with the
drop_label() function. For example:
new_demographics_table <- drop_label(demographics, "name_first")
# Or
new_demographics_table <- drop_label(demographics, name_first)
# Or
new_demographics_table <- demographics |> drop_label("name_first")Drop multiple labels
If you need to drop labels from multiple variables, you can drop them
individually or using helper methods (i.e., across()).
demographics |>
mutate(age = drop_label(age)) |>
mutate(days = drop_label(days)) |>
rowwise() |>
mutate(x = sum(c_across(c(age, days))))
# Or
demographics |>
mutate(across(c(age, days), drop_label)) |>
rowwise() |>
mutate(x = sum(c_across(c(age, days))))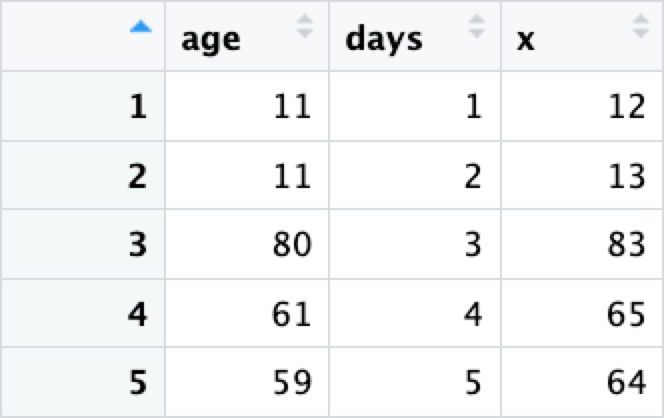
You can use tidyselect helper methods (i.e.,
contains() or starts_with()) to include more
than one variable or list them. The following code produces the same
result:
demographics_changed_2 <- drop_label(demographics, contains("name"))
# Same as:
demographics_changed_3 <- drop_label(demographics, name_first, name_last)
# Verifying:
identical(demographics_changed_2, demographics_changed_3)NOTE: You do not normally need to enclose the variable names in quotations outside of
tidyselecthelpers (i.e.,contains()) though the function still operates if you choose to.
Use inside a mutate
You can now use drop_label() inside a
mutate pipe like this:
demographics_from_mutate <- demographics |>
mutate(name_first = drop_label(name_first))
# Or
demographics_from_mutate <- demographics |>
mutate(across(starts_with('name'), drop_label))Drop all dataset variable labels
You can drop all the labels using the drop_label()
function. For example:
demographics_without_labels <- drop_label(demographics)NOTE: tidyREDCap versions prior to 1.2.0 handled dropping all variable labels from a dataset by using
drop_labels(). This function can still be used, but we added a polite message to usedrop_label()instead.
demographics_without_labels <- drop_labels(demographics)
#> Warning: `drop_labels()` was deprecated in tidyREDCap 1.2.0.
#> ℹ Please use `drop_label()` instead.
#> This warning is displayed once per session.
#> Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
#> generated.